引子
当单机数据库无法满足Web应用的高并发需求时,就需要考虑对数据库做集群。目前,数据库集群主要关注点有两个方面:
- 配置Mysql原生主从复制,进行读写分离;
- 根据业务关系和数据表规模,进行分库分表。
对于第一个方面,Mysql主从复制和读写分离方案分析有详细说明,有兴趣的同学可以移步参考。本篇的主角仍然是Amoeba,主要介绍如何使用它完成对Mysql的分库分表操作。
关于数据库分库分表的基本原理(或者叫数据库垂直切分和水平切分),可以参考数据库Sharding的基本思想和切分策略。
其中,垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。

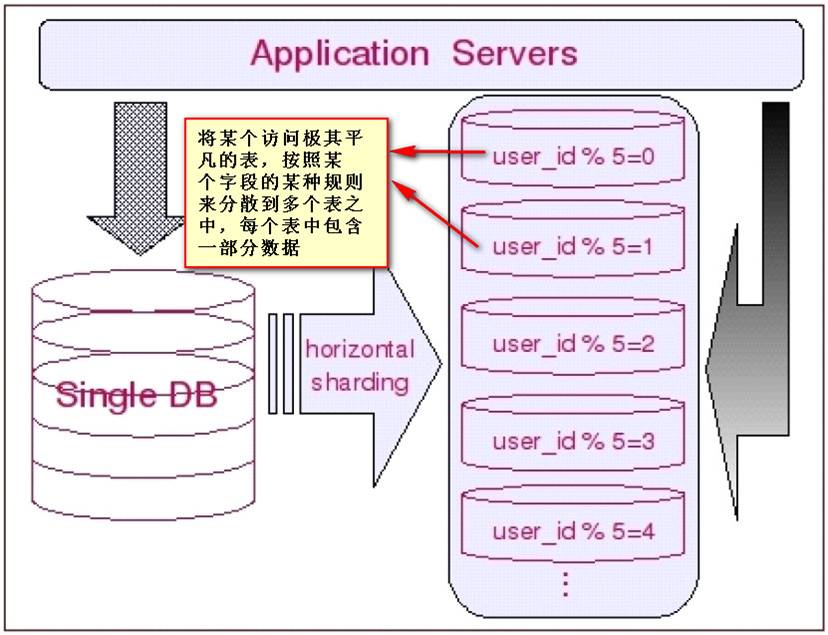
水平切分于垂直切分相比,相对来说稍微复杂一些,因为要将同一个表中的不同数据拆分到不同的数据库中。通常根据表中的某列数据或某几列数据定义切分规则,例如根据数据表ID区间或时间字段区间。
原型环境
- 服务器A
IP: 1XX.XX.XX.181
运行Mysql主数据库和Amoeba。
- 服务器B
IP: 1XX.XX.XX.185
运行Mysql从数据库。
操作系统版本
[root@chenllcentos ~]# cat /etc/redhat-release
CentOS release 6.5 (Final)
具体流程
同读写分离的情形相同,Amoeba在进行库表切分的时候也是以中间件的形式存在的。因此,此库表切分方案对应用层完全透明。整个流程主要包括三个阶段,现分别说明如下。
数据库访问授权
对于客户端来说,直接建立连接的是Amoeba数据库代理,Amoeba将接收到的SQL语句做路由,转发到真实Mysql数据库。由此可见,Amoeba所在的主机必须具有访问所代理的数据库权限。在本例子中,需要给服务器A授权。
登录服务器B数据库:
[root@chenllcentos ~]# mysql -uroot -pyourpassword
分配访问权限给服务器A:
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'1XX.XX.XX.181' IDENTIFIED BY 'root' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
准备数据表
测试数据库以博客系统为原型,使用test数据库,分别定义t_user表、t_blog表、t_message表、t_attention表和t_blog_comment表。其中t_user表、t_blog表和t_message表在服务器A中,而t_attention表和t_blog_comment表在服务器B。
登录服务器A数据库:
[root@chenllcentos ~]# mysql -uroot -pyourpassword -h1XX.XX.XX.181 -P3306
创建t_user表:
mysql> create table test.t_user (
-> user_id integer unsigned not null,
-> user_name varchar(45),
-> user_address varchar(100),
-> primary key (user_id)
-> )engine=innodb;
创建t_blog表:
mysql> create table test.t_blog (
-> blog_id integer unsigned not null,
-> blog_title varchar(45),
-> blog_content text,
-> user_id integer,
-> primary key (blog_id)
-> )engine=innodb;
创建t_message表:
mysql> create table test.t_message (
-> message_id integer unsigned not null,
-> message_content varchar(255),
-> user_id integer
-> )engine=innodb;
同样的,登录服务器B数据库:
[root@chenllcentos ~]# mysql -uroot -pyourpassword -h1XX.XX.XX.185 -P3306
创建t_user表,用于水平切割:
mysql> create table test.t_user (
-> user_id integer unsigned not null,
-> user_name varchar(45),
-> user_address varchar(100),
-> primary key (user_id)
-> )engine=innodb;
创建t_attention表:
mysql> create table test.t_attention (
-> attention_id integer unsigned not null,
-> user_id integer,
-> blog_id integer
-> )engine=innodb;
创建t_blog_comment表:
mysql> create table test.t_blog_comment (
-> comment_id integer unsigned not null,
-> commnet_content text,
-> blog_id integer
-> )engine=innodb;
Amoeba配置
Amoeba配置主要包括dbServers.xml、amoeba.xml和rule.xml三个配置文件的配置。其中dbServers.xml和amoeba.xml在Mysql主从复制和读写分离方案分析已经做了详细介绍,此处直接列出。
dbServers.xml内容:
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:dbServers SYSTEM "dbserver.dtd">
<amoeba:dbServers xmlns:amoeba="http://amoeba.meidusa.com/">
<!--
Each dbServer needs to be configured into a Pool,
If you need to configure multiple dbServer with load balancing that can be simplified by the following configuration:
add attribute with name virtual = "true" in dbServer, but the configuration does not allow the element with name factoryConfig
such as 'multiPool' dbServer
-->
<!-- 该dbServer节点abstractive="true",包含Mysql的公共配置信息,其他dbServer节点都继承该节点 -->
<!-- 设置节点配置的继承结构,可以避免重复配置相同信息,减少配置文件冗余 -->
<dbServer name="abstractServer" abstractive="true">
<factoryConfig class="com.meidusa.amoeba.mysql.net.MysqlServerConnectionFactory">
<property name="connectionManager">${defaultManager}</property>
<property name="sendBufferSize">64</property>
<property name="receiveBufferSize">128</property>
<!-- mysql port -->
<!-- Mysql默认端口 -->
<property name="port">3306</property>
<!-- mysql schema -->
<!-- 默认连接的数据库,若不存在需要事先创建,否则Amoeba启动报错 -->
<property name="schema">test</property>
<!-- mysql user -->
<property name="user">root</property>
<property name="password">root</property>
</factoryConfig>
<poolConfig class="com.meidusa.toolkit.common.poolable.PoolableObjectPool">
<property name="maxActive">500</property>
<property name="maxIdle">500</property>
<property name="minIdle">1</property>
<property name="minEvictableIdleTimeMillis">600000</property>
<property name="timeBetweenEvictionRunsMillis">600000</property>
<property name="testOnBorrow">true</property>
<property name="testOnReturn">true</property>
<property name="testWhileIdle">true</property>
</poolConfig>
</dbServer>
<!-- master节点继承abstractServer -->
<dbServer name="master" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<!-- master数据库主机地址 -->
<property name="ipAddress">1XX.XX.XX.181</property>
</factoryConfig>
</dbServer>
<!-- slave节点继承abstractServer -->
<dbServer name="slave" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<!-- slave数据库主机地址 -->
<property name="ipAddress">1XX.XX.XX.182</property>
</factoryConfig>
</dbServer>
<!-- slave1节点继承abstractServer -->
<dbServer name="slave1" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<!-- slave1数据库主机地址 -->
<property name="ipAddress">1XX.XX.XX.183</property>
</factoryConfig>
</dbServer>
<dbServer name="server1" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<property name="ipAddress">1XX.XX.XX.181</property>
</factoryConfig>
</dbServer>
<dbServer name="server2" parent="abstractServer">
<factoryConfig>
<!-- mysql ip -->
<!-- server2数据库主机地址 -->
<property name="ipAddress">1XX.XX.XX.185</property>
</factoryConfig>
</dbServer>
<!-- 配置数据库读取连接池 -->
<dbServer name="readPool" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
<!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA-->
<property name="loadbalance">1</property>
<!-- Separated by commas,such as: server1,server2,server1 -->
<property name="poolNames">slave,slave1</property>
</poolConfig>
</dbServer>
</amoeba:dbServers>
amoeba.xml内容:
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:configuration SYSTEM "amoeba.dtd">
<amoeba:configuration xmlns:amoeba="http://amoeba.meidusa.com/">
<proxy>
<!-- service class must implements com.meidusa.amoeba.service.Service -->
<service name="Amoeba for Mysql" class="com.meidusa.amoeba.mysql.server.MySQLService">
<!-- port -->
<property name="port">8066</property>
<!-- bind ipAddress -->
<!--
<property name="ipAddress">1XX.XX.XX.181</property>
-->
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.mysql.net.MysqlClientConnectionFactory">
<property name="sendBufferSize">128</property>
<property name="receiveBufferSize">64</property>
</bean>
</property>
<property name="authenticateProvider">
<bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator">
<property name="user">root</property>
<property name="password">root</property>
<property name="filter">
<bean class="com.meidusa.toolkit.net.authenticate.server.IPAccessController">
<property name="ipFile">${amoeba.home}/conf/access_list.conf</property>
</bean>
</property>
</bean>
</property>
</service>
<runtime class="com.meidusa.amoeba.mysql.context.MysqlRuntimeContext">
<!-- proxy server client process thread size -->
<property name="executeThreadSize">128</property>
<!-- per connection cache prepared statement size -->
<property name="statementCacheSize">500</property>
<!-- default charset -->
<property name="serverCharset">utf8</property>
<!-- query timeout( default: 60 second , TimeUnit:second) -->
<property name="queryTimeout">60</property>
</runtime>
</proxy>
<!--
Each ConnectionManager will start as thread
manager responsible for the Connection IO read , Death Detection
-->
<connectionManagerList>
<connectionManager name="defaultManager" class="com.meidusa.toolkit.net.MultiConnectionManagerWrapper">
<property name="subManagerClassName">com.meidusa.toolkit.net.AuthingableConnectionManager</property>
</connectionManager>
</connectionManagerList>
<!-- default using file loader -->
<dbServerLoader class="com.meidusa.amoeba.context.DBServerConfigFileLoader">
<property name="configFile">${amoeba.home}/conf/dbServers.xml</property>
</dbServerLoader>
<queryRouter class="com.meidusa.amoeba.mysql.parser.MysqlQueryRouter">
<property name="ruleLoader">
<bean class="com.meidusa.amoeba.route.TableRuleFileLoader">
<property name="ruleFile">${amoeba.home}/conf/rule.xml</property>
<property name="functionFile">${amoeba.home}/conf/ruleFunctionMap.xml</property>
</bean>
</property>
<property name="sqlFunctionFile">${amoeba.home}/conf/functionMap.xml</property>
<property name="LRUMapSize">1500</property>
<property name="defaultPool">server1</property>
<property name="writePool">server1</property>
<property name="readPool">server1</property>
<property name="needParse">true</property>
</queryRouter>
</amoeba:configuration>
这里重点介绍rule.xml配置。先看看在本例中的配置内容:
<?xml version="1.0" encoding="gbk"?>
<!DOCTYPE amoeba:rule SYSTEM "rule.dtd">
<amoeba:rule xmlns:amoeba="http://amoeba.meidusa.com/">
<tableRule name="t_user" schema="test" defaultPools="server1,server2">
<rule name="rule1">
<parameters>user_id</parameters>
<expression><![CDATA[ user_id % 2 == 0 ]]></expression>
<defaultPools>server1</defaultPools>
</rule>
<rule name="rule2">
<parameters>user_id</parameters>
<expression><![CDATA[ user_id % 2 == 1 ]]></expression>
<defaultPools>server2</defaultPools>
</rule>
</tableRule>
<tableRule name="t_attention" schema="test" defaultPools="server2" />
<tableRule name="t_blog_comment" schema="test" defaultPools="server2" />
</amoeba:rule>
其中,server1和server2是在dbServers.xml中配置的真实数据库节点。当客户端操作t_attention表和t_blog_comment表时,连接的是server2服务器;当客户端操作其余表时,连接的是server1服务器。这样,就实现了数据库垂直切分功能。当客户端操作t_user表时,rule1和rule2生效。此时若user_id为奇数,Amoeba连接sever2;若user_id为偶数,Amoeba连接sever1。这样,也就实现了数据库水平切分。当然上述规则只是个简单的例子,实际情况可能会复杂许多,但配置的流程是不变的,都是修改
切分验证
启动Amoeba代理:
[root@chenllcentos ~]# /usr/local/amoeba-mysql-3.0.5-RC/bin/launcher
使用Amoeba代理登陆数据库:
[root@chenllcentos ~]# mysql -uroot -pyourpassword -h1XX.XX.XX.181 -P8066
注意,这里登录的是Amoeba代理(端口号8066),而不是真实Mysql数据库。
打开test数据库:
mysql> use test;
Database changed
查看test数据库表:
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| t_blog |
| t_message |
| t_user |
+----------------+
3 rows in set (0.00 sec)
由于主数据库和Amoeba都安装在服务器A上,因此可以查看到t_blog表、t_message表和t_user表。那么,另外两张表呢?如果切分成功,应该可以在Amoeba上进行查询,试试看。
mysql> select * from t_blog_comment;
Empty set (0.00 sec)
可以发现,并没有报找不到t_blog_comment表错,说明我们的数据库切分是有效的。同样的,我们也能够访问t_attention表:
mysql> select * from t_attention;
Empty set (0.00 sec)
现在,让我们插几条数据试试。
mysql> insert into test.t_user (user_id, user_name, user_address) values (1, 'Lucy', 'Xiamen');
mysql> insert into test.t_user (user_id, user_name, user_address) values (2, 'John', 'Beijing');
mysql> insert into test.t_user (user_id, user_name, user_address) values (3, 'Mike', 'Fuzhou');
mysql> insert into test.t_blog (blog_id, blog_title, blog_content, user_id) values (1, 'My First Blog', 'This is content', 1);
mysql> insert into test.t_blog_comment (comment_id, commnet_content, blog_id) values (1, 'Hello world', 1);
查询t_user表数据:
mysql> select * from t_user;
+---------+-----------+--------------+
| user_id | user_name | user_address |
+---------+-----------+--------------+
| 2 | John | Beijing |
+---------+-----------+--------------+
1 row in set (0.00 sec)
由于此时登录的是服务器A,因此该服务器上的t_user表保存用户ID为偶数的用户。可以验证,数据库水平切分生效。
那么,我们来看看用户ID为奇数的用户是否成功保存。
登录服务器B数据库:
[root@chenllcentos ~]# mysql -uroot -proot
打开test数据库:
mysql> use test;
查询用户表t_user:
mysql> select * from t_user;
+---------+-----------+--------------+
| user_id | user_name | user_address |
+---------+-----------+--------------+
| 1 | Lucy | Xiamen |
| 3 | Mike | Fuzhou |
+---------+-----------+--------------+
2 rows in set (0.00 sec)
可以看出,用户ID为奇数的用户数据已成功保存至服务器B数据库。
最后,再验证下垂直切分。回想下刚才的配置过程,我们将t_blog_comment表放在服务器B的test数据库里,让我们看看刚才插入的数据是否存在。
mysql> use test;
mysql> select * from t_blog_comment;
+------------+-----------------+---------+
| comment_id | commnet_content | blog_id |
+------------+-----------------+---------+
| 1 | Hello world | 1 |
+------------+-----------------+---------+
1 row in set (0.00 sec)
意料之中,t_blog_comment表的数据已成功保存。
小结
通过以上介绍可以感觉到,使用Amoeba作为中间件,无论是进行数据库读写分离还是分库分表,都是通过直接修改xml配置文件实现的,整个过程与应用层完全解耦。如果存在一个已经上线的项目,使用Amoeba可以在不改动Web应用的前提下,完成数据库集群。当然,Amoeba并不支持数据库事务,如果线上系统对数据库事务的要求很严格,那么Amoeba并不合适。